Transformer Architecture
7/30The Transformer Revolution
Introduced in the 2017 paper "Attention is All You Need" by Google researchers, the Transformer architecture revolutionized natural language processing:
- Processes entire sequences in parallel (unlike RNNs)
- Models interactions between all tokens (not just nearby ones)
- Enables much deeper networks with stable training
- Highly scalable to massive model sizes
The Original Transformer
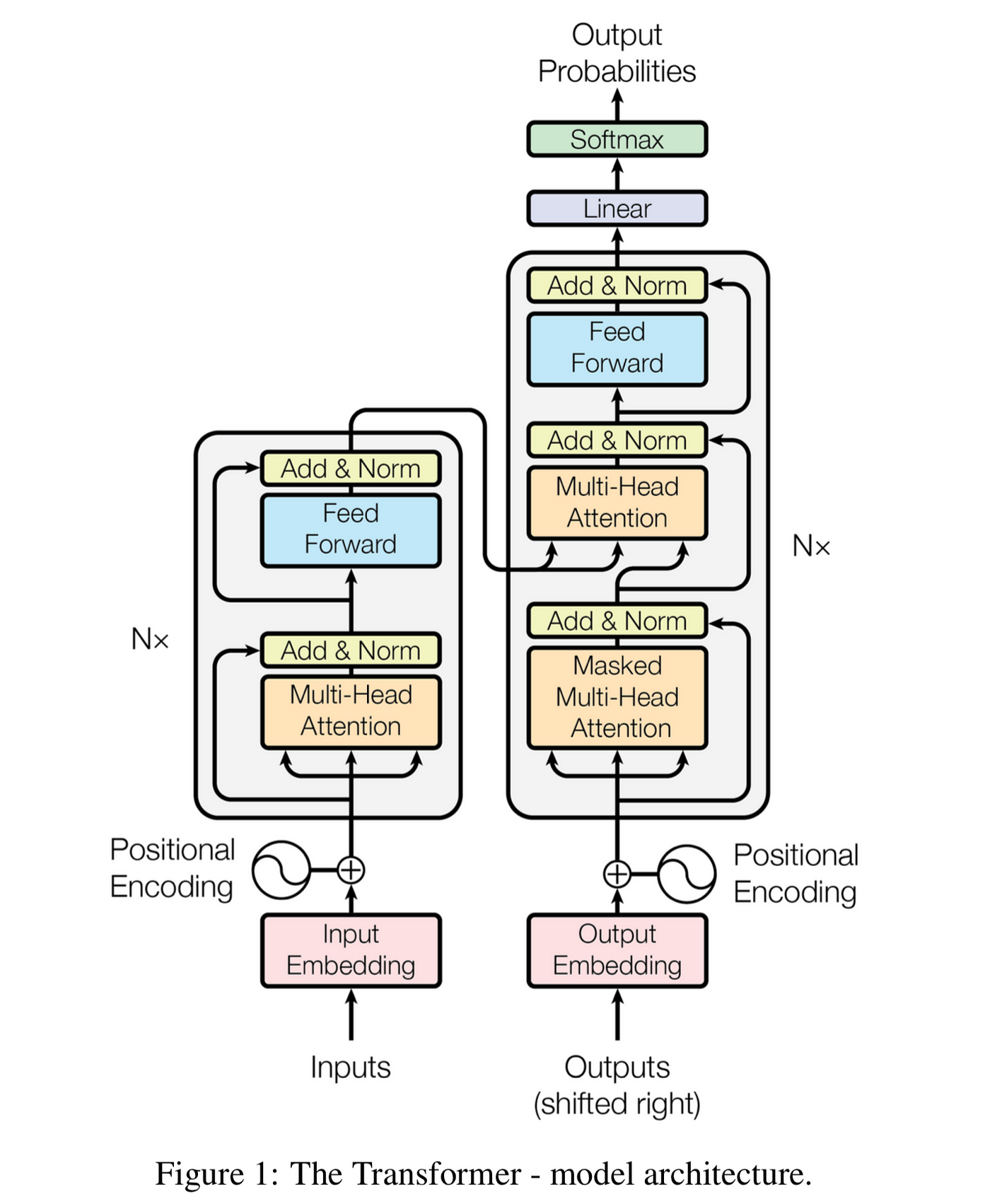
Source: "Attention is All You Need" (Vaswani et al., 2017)
Key Components
Self-Attention Layer
Allows each token to "look at" all other tokens and gather relevant information from them based on learned relevance scores.
Feed-Forward Networks
Apply the same transformation to each token independently, typically consisting of two linear transformations with a non-linear activation in between.
Residual Connections
Allow deep networks to train stably by providing shortcuts for gradient flow during backpropagation.
Layer Normalization
Normalizes activations within each layer to stabilize training and speed up convergence.
Position Encodings
Add information about token positions since self-attention itself is position-agnostic.
Transformer Block Structure
A single transformer block with residual connections (dashed lines)
Stacking for Depth
Modern LLMs stack these blocks to create deep networks:
- BERT-base: 12 layers
- GPT-3: 96 layers
- GPT-4: ~120 layers (estimated)
- Larger models: 200+ layers
Key Scaling Factors for LLMs
Depth
Number of transformer blocks stacked together
Width
Dimension of embeddings and hidden layers
Heads
Number of parallel attention mechanisms per layer