Self-Attention Mechanism
8/30What is Self-Attention?
Self-attention is the key innovation of the Transformer architecture that allows each token to directly interact with all other tokens in the sequence.
Core Idea
For each position in a sequence:
- Calculate how much attention to pay to every other position
- Create a weighted sum of all token representations
- This enables the model to capture long-range dependencies
Advantages Over Previous Methods
| Method | Limitation |
|---|---|
| Recurrent (RNN) | Information must pass through all intermediate states, leading to vanishing gradients |
| Convolutional (CNN) | Limited receptive field, needs many layers to capture long-range patterns |
| Self-Attention | Direct connections between any tokens, regardless of distance |
Self-Attention Visualization
Attention Example
Consider the phrase: "The animal didn't cross the street because it was too tired."
| The | animal | didn't | cross | the | street | because | it | was | too | tired | |
| it | 0.01 | 0.85 | 0.05 | 0.01 | 0.01 | 0.01 | 0.02 | - | 0.01 | 0.01 | 0.02 |
When processing "it", the model heavily attends to "animal", correctly resolving the reference.
Attention Patterns
Syntactic Attention

Semantic Attention

Different attention heads learn to focus on different linguistic patterns
Self-Attention Calculation
The Math Behind Self-Attention
For each token, compute:
-
Query (Q), Key (K), Value (V)
Linear projections of each token embedding
-
Attention Scores
How much each token should attend to others
Score = Q·KT / √dk -
Attention Weights
Apply softmax to scores to get weights
-
Output
Weighted sum of value vectors
Output = softmax(QKT / √dk)·V
Multi-Head Attention
Instead of a single attention mechanism, the model uses multiple "heads" in parallel:
- Each head can focus on different aspects of the input (syntax, semantics, etc.)
- Outputs from all heads are concatenated and projected
- Typical models use 8-128 attention heads
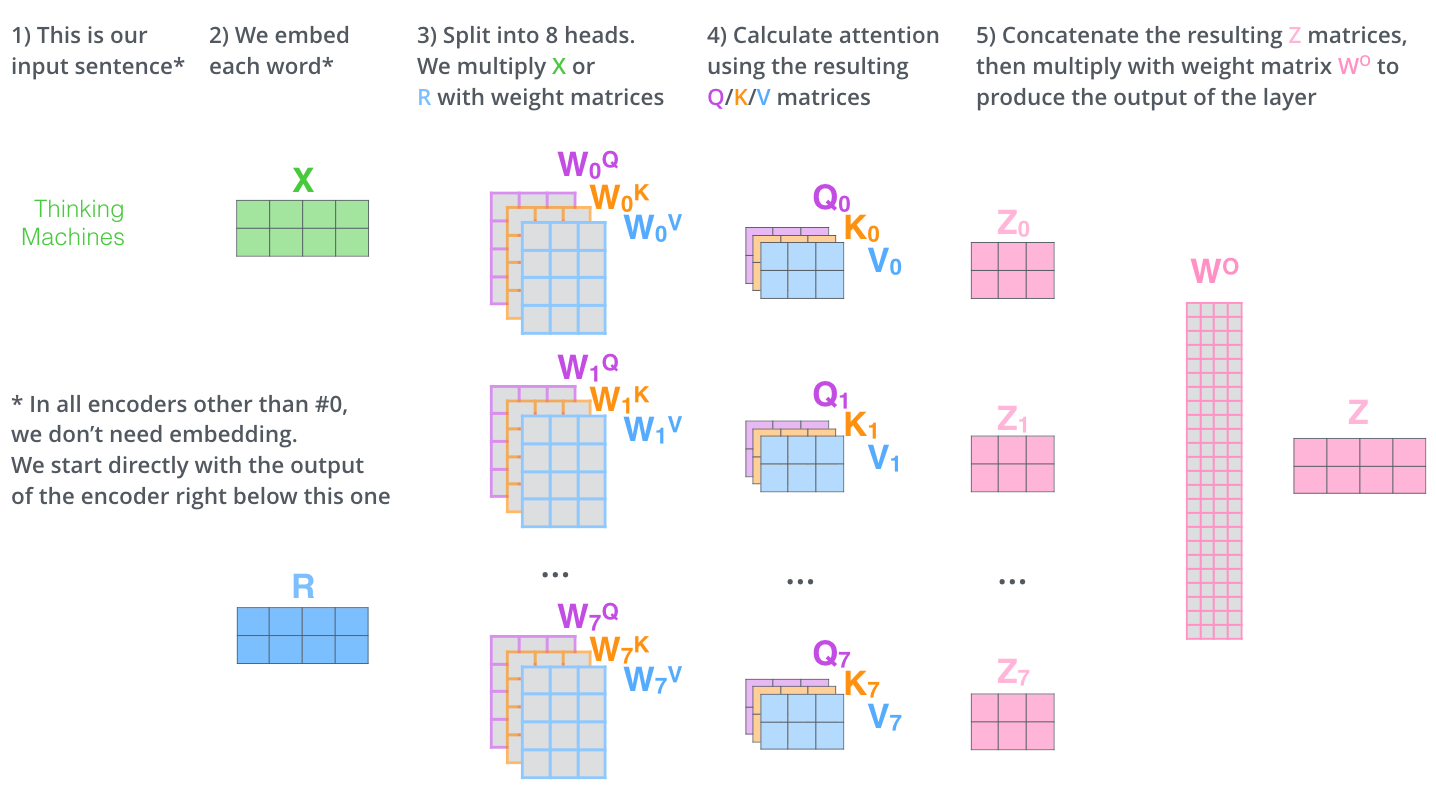
Each attention head focuses on different aspects of the input